
Building Blocks of Docker Containers
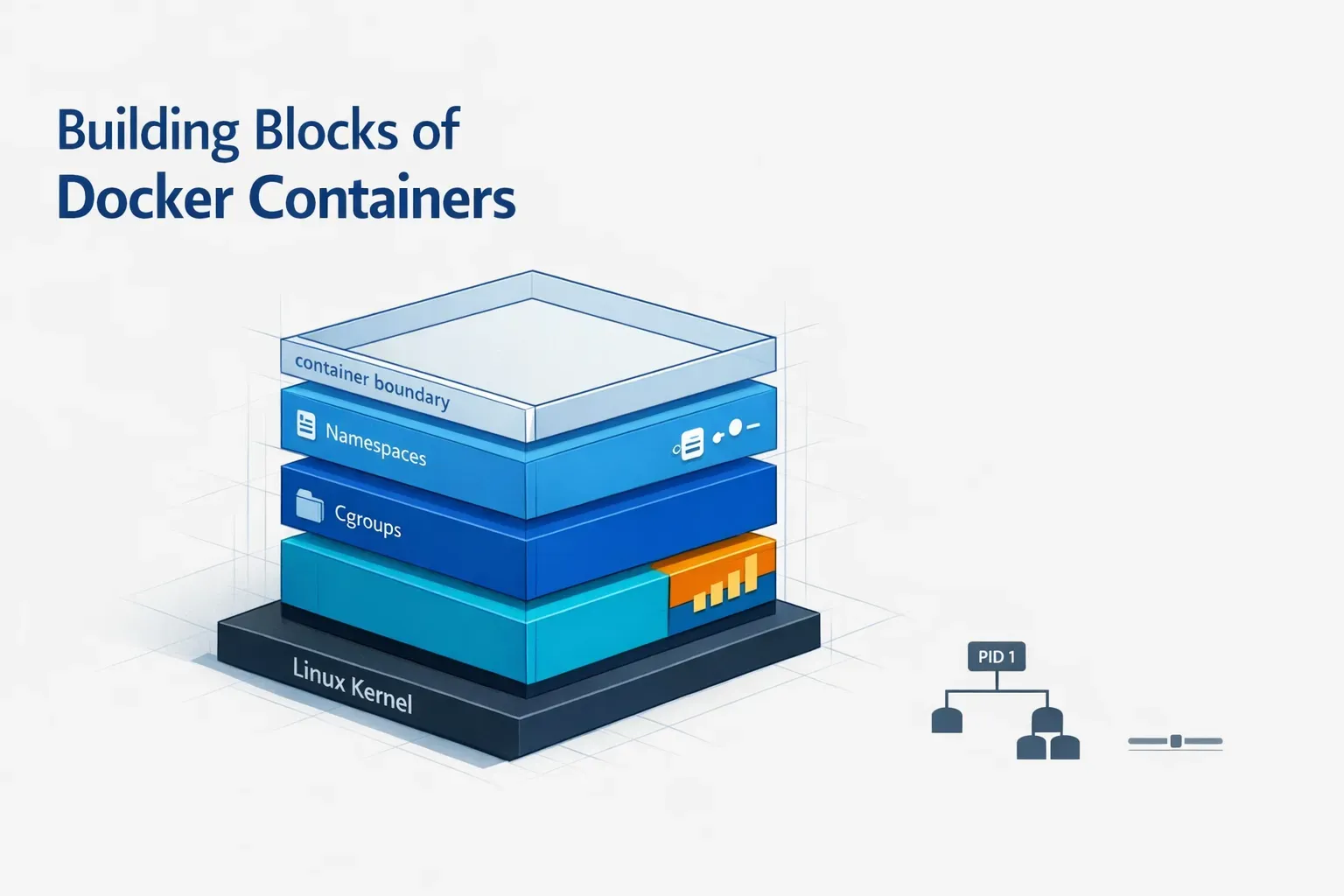
Introduction
In this blog, we will explore how Docker containers achieve isolation from the host system using key concepts like namespaces and cgroups. Through a hands-on exercise, we’ll demonstrate how to create your own isolated container and limit resources to it.
Architecture of docker
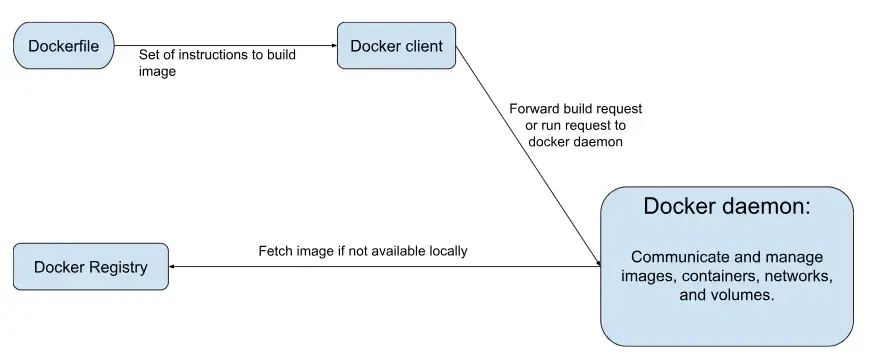
Letʼs have a look at the basic architecture of docker, which contains three main components.
- Docker Daemon (dockerd): This is the component that listens for Docker API requests and manages Docker objects like images, containers, networks, and volumes.
- Docker Client: This is the interface that communicates with the Docker daemon. It sends requests via the Docker API to perform actions such as building images, running containers, and managing Docker objects.
- Docker Registry: This is a centralized repository for Docker images. It allows users to share and distribute their images. Docker Hub is an example of a Docker registry with a vast collection of public images that anyone can pull and use. However, for the blog it’s not necessary to understand the basic working of docker and you can consider it as a pip or npm for docker.
The basic workflow of Docker
In this section, we will delve into how the Docker daemon runs Docker images in an isolated environment and communicates with the host system.
Container isolation
Docker uses a number of Linux kernel capabilities, such as namespaces and control groups (cgroups), to enable container isolation. In order to construct our own container, The OS ideas about namespaces that we should be aware of are:
Namespaces:
A kernel feature called namespaces enables processes to operate in a segregated environment apart from the rest of the system. We need to make system calls to build it. Letʼs learn briefly about different namespaces.
- UTS namespace: Isolates a container’s hostname and domain name so that every container can have a distinct hostname and domain independent from the host system. Useful in lightweight containerization where you might want to give each container a unique hostname but share the same network.
- PID namespace: In order to guarantee that every container has a distinct set of process IDs, the PID namespace separates the process ID (PID) space. Within the same container, processes are able to see and communicate with one another.
- Network namespace: Assign distinct IP addresses, routing tables, firewall rules, and networking interfaces to every process in the network namespace. Essential for complex network isolation, such as in container orchestration systems like Kubernetes, where each pod/container needs its own network environment.
- Mount namespaces: Assures separate, segregated filesystem mount points for every container. Changes made to a container’s file system are separated from those made to other containers or the host system. Each container has its own root system for files.
- Inter-process communication (IPC) namespace: Isolates semaphores and shared memory. For container A and B, If both containers need to use shared memory, semaphores, or message queues, the IPC namespace ensures they don’t interfere with each otherʼs IPC mechanisms.
- File system namespaces: The Linux filesystem is arranged like a tree, with a root that is commonly denoted by ’/’. The namespace will map a node in the filesystem tree to a virtual root inside that namespace in order to establish isolation on a filesystem level. Linux prevents you from browsing the filesystem outside of your virtualized root when browsing within that namespace.
Cgroups:
Cgroups are kernel features that enable the management and isolation of system resources. They allow administrators to partition system resources, set limits on resource usage, and prioritize processes. Cgroups operate by grouping together a set of processes and their descendants, and then applying resource constraints or policies to these groups.
Controllers are the driving force behind cgroups, enabling administrators to exert control over various system resources. Each controller manages a specific set of system resources, such as CPU, memory, or I/O bandwidth. By manipulating parameters within these controllers, administrators can dictate how resources are allocated and utilized by processes within cgroups.cpu
- CPU: Cgroups ensure that a group of tasks gets a minimum amount of CPU time when the system is busy. It doesn’t limit how much CPU time the group can use if the CPUs aren’t busy.
- Cpuset: This cgroup binds tasks to specific CPUs and memory areas.
- Freezer: The freezer cgroup can pause and resume all tasks in a group.
- Hugetlb: This cgroup helps control the use of large memory pages.
- Io: The io cgroup manages access to specific storage devices by setting limits on data read from or written to them.
- Memory: The memory controller keeps track of and sets limits on process memory, including both regular and swap memory.
- Perf_event: This controller allows for performance monitoring of all tasks in a group.
- Pids: The pids controller limits the number of processes that can be created within a group and its subgroups.
- Rdma: The RDMA controller limits the use of RDMA/IB-related resources per group.
Build Your Own Container
Let’s create a container using the namespace and cgroup concepts in Golang as docker is also written in Golang.
Isolation from host system
Letʼs create a basic container with UTS namespace .Processes (programs) running within a specific UTS namespace can have their own hostname, independent of the main system hostname or other UTS namespaces.
In order to get the idea what is hostname and why UTS namespace is important ?
- https://serverfault.com/questions/228102/hostnames-what-are-they-all-about
- https://man7.org/linux/man-pages/man7/uts_namespaces.7.html
Basic go setup
Installation and prerequisites for go-lang.
Hands on exercise
package main
import (
"fmt"
"os"
"os/exec"
"syscall"
)
// go run main.go run <cmd> <params>
func main(){
switch os.Args[1]{
case "run":
run()
default:
panic("BAD COMMAND")
}
}
func run(){
fmt.Printf("Running %v as PID:%d\n", os.Args[2:], os.Getpid())
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
// Containerize commands by creating namespaces
cmd.SysProcAttr = &syscall.SysProcAttr{
// Cloning is what creates new process that we are gonna run arbitrary command
Cloneflags: syscall.CLONE_NEWUTS, //New unix sharing systems.
}
must(cmd.Run())
}
func must(err error){
if (err != nil){
panic(err)
}
}Since we are interacting with syscalls, we need sudo privileges before running the program. Therefore, let’s switch to the root user and then run the program.

Letʼs check that we have isolated the host system from root by changing hostname inside the container.

We have the first proof that whatever hostname we change inside the container doesnʼt get affected outside the container. Now letʼs add a new process namespace to get new process ids.
// go run main.go run <cmd> <params>
func main() {
switch os.Args[1] {
case "run":
run()
case "child":
child()
default:
panic("help")
}
}
func run() {
fmt.Printf("Running %v as PID:%d\n", os.Args[2:], os.Getpid())
// Re invoke this process inside it's new namespace but 2nd time it'll call child
cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
// Containerize commands by creating namespaces
cmd.SysProcAttr = &syscall.SysProcAttr{
// Cloning is what creates new process that we are gonna run arbitrary command
Cloneflags: syscall.CLONE_NEWUTS | //New unix sharing systems.
syscall.CLONE_NEWPID,
}
// can't set hostname after cmd.run because process has already been executed.
// can't set hostname before cmd.run because new process isn't executed so new container is not created yet.
// So set hostname in child
must(cmd.Run())
}
func child() {
fmt.Printf("Running child%v as PID:%d\n", os.Args[2:], os.Getpid())
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
must(syscall.Sethostname([]byte("container")))
must(cmd.Run())
}root@rita:~/preet/docker_exp# go run main.go run /bin/bash
Running [/bin/bash] as PID:37545
Running child[/bin/bash] as PID:1
root@container:~/preet/docker_exp# hostname
containerHere we can see two changes:
- The child has a new process id because of syscall.CLONE_NEWPID. The PID namespace allows one to spin off a new tree, with its own PID 1 process.
- In the terminal hostname has been changed to container because of CLONE_NEWUTS.
If we execute the ps command, will all the processes running inside the container have new process IDs?
root@rita:~/preet/docker_exp# ps
PID TTY TIME CMD
7133 pts/4 00:00:00 sudo
7134 pts/4 00:00:00 su
7142 pts/4 00:00:00 bash
8040 pts/4 00:00:00 go
8125 pts/4 00:00:00 main
8130 pts/4 00:00:00 exe
8135 pts/4 00:00:00 bash
8173 pts/4 00:00:00 ps
root@rita:~/preet/docker_exp# exitIt still has process ids from root because ps gets process ids directly from /proc directory. Here we have not isolated the root directory ( / ) from the host. So ps will get processes from the root directory which is maintained by the host system. Just to confirm you can check the result of ls /proc from inside the container as well as outside the container are the same.
To isolate the root, we need to obtain a different root-fs from the host. Let’s acquire a fresh Ubuntu from the Docker Hub and extract the root-fs from it. We will then use this root-fs within our container. This step corresponds to the FROM ubuntu:latest instruction in the Dockerfile.
docker run -d --rm --name ubuntufs ubuntu:20.04 sleep 1000
docker export ubuntufs -o ubuntufs.tar
docker stop ubuntufs
mkdir -p /home/preet/ubuntufs
tar xf ubuntufs.tar -C /home/preet/ubuntufs/
# Just to verify different root we create CONTAINER_ROOT file.
touch /home/preet/ubuntufs/CONTAINER_ROOTAdjust the child function as shown below to change the root directory inside the container.
func child() {
fmt.Printf("Running child%v as PID:%d\n", os.Args[2:], os.Getpid())
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
syscall.Sethostname([]byte("container"))
syscall.Chroot("/home/preet/ubuntufs")
syscall.Chdir("/")
// Mounting a separate /proc within this new environment allows the processes inside
// to have their own view of running processes,
// independent of the host system or other containers.
syscall.Mount("proc", "proc", "proc", 0, "")
must(cmd.Run())
syscall.Unmount("/proc", 0)
}
Success! We have managed to generate new process IDs inside our container. This is a significant step as it indicates that our container processes are now isolated from the main system. Furthermore, The presence of CONTAINER_ROOT is a clear indication that we have successfully changed the root-fs inside our container.
root@rita:~/preet/docker_exp# # Let's reach to another terminal and check outside of the container
root@rita:~/preet/docker_exp# ps fax
............
............
12719 ? Ssl 0:53 \_ /usr/libexec/gnome-terminal-server
12732 pts/0 Ss+ 0:00 | \_ bash
14148 pts/3 Ss 0:00 | \_ bash
34252 pts/3 S+ 0:00 | | \_ sudo su
34253 pts/1 Ss 0:00 | | \_ sudo su
34254 pts/1 S 0:00 | | \_ su
34255 pts/1 S 0:00 | | \_ bash
36125 pts/1 Sl 0:00 | | \_ go run main.go run /bin
36179 pts/1 Sl 0:00 | | \_ /tmp/go-build289551
36184 pts/1 Sl 0:00 | | \_ /proc/self/exe
36189 pts/1 S+ 0:00 | | \_ /bin/bash
............
............
This demonstrates that we can view all processes occurring inside the container from the host machine. However from inside, we’re unable to see the processes outside the container.
# From inside the container
root@container:/# mount
proc on /proc type proc (rw,relatime)# From other terminal, outside the container
root@rita:~/preet/docker_exp# mount | grep proc
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
systemd-1 on /proc/sys/fs/binfmt_misc type autofs (rw,relatime,fd=32,pgrp=1,timeout=0,minproto=5,maxproto=5,direct,pipe_ino=4452)
binfmt_misc on /proc/sys/fs/binfmt_misc type binfmt_misc (rw,nosuid,nodev,noexec,relatime)
proc on /home/preet/ubuntufs/proc type proc (rw,relatime)
root@rita:~/preet/docker_exp#Unshare
Here, we see the mounted /home/preet/ubuntufs/proc. If we don’t want to share mount information with the host, we have a mount namespace, referred to as Namespace. It was the first namespace which was created. There were no namespaces before that, so they called it Namespace . By default, this is shared with the host system. We can add a Namespace and instruct the kernel not to share this Namespace with the host. This can be achieved using unshare.
Let’s modify run() function
func run() {
………………………………………………………………………
………………………………………………………………………
………………………………………………………………………
// Containerize commands by creating namespaces
cmd.SysProcAttr = &syscall.SysProcAttr{
// Cloning is what creates new process that we are gonna run arbitrary command
Cloneflags: syscall.CLONE_NEWUTS | //New unix sharing systems.
syscall.CLONE_NEWPID |
syscall.CLONE_NEWNS, // Namespace for mounts.
// By default under systemd, Mounts get recursively shared property
// And at the moment root directory on my host is recursively shared b/w all namespaces for any mounts.
// To turn off that we have unshare
Unshareflags: syscall.CLONE_NEWNS,
// This mount NS in container will not be shared with the host. By default it would have shared to host.
}
………………………………………………………………………
………………………………………………………………………
………………………………………………………………………
}
# From inside the container
root@container:/# mount
proc on /proc type proc (rw,relatime)
# From other terminal, outside the container
root@rita:~# mount | grep proc
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
systemd-1 on /proc/sys/fs/binfmt_misc type autofs (rw,relatime,fd=32,pgrp=1,timeout=0,minproto=5,maxproto=5,direct,pipe_ino=4452)
binfmt_misc on /proc/sys/fs/binfmt_misc type binfmt_misc (rw,nosuid,nodev,noexec,relatime)
root@rita:~#Cgroups
Now, we’ll walk through the process of creating a new control group (cgroup) in Linux and using it to mitigate the impact of fork bombs. Fork bombs are malicious scripts or programs that rapidly create a large number of processes, overwhelming system resources and causing it to become unresponsive. By confining processes within a specific cgroup, we can limit their ability to spawn excessive processes.
Step 1: Create a New Cgroup
Cgroups in Linux are present in the directory /sys/fs/. First, let’s create a new directory in the cgroups filesystem (/sys/fs/cgroup) to hold our new cgroup. We’ll name our cgroup “test_cgroup”, but you can choose any name you prefer.
preet@nymphadora:~/# sudo mkdir /sys/fs/cgroup/test_cgroupStep 2: Set Maximum Number of Processes
At this moment executing the below command will return us max which states that any number of processes would be allowed to create in the cgroup.
preet@nymphadora:~/# cat /sys/fs/cgroup/test_cgroup/pids.max
max
preet@nymphadora:~/#So, we need to redefine the maximum number of processes allowed within the “test_cgroup”. We’ll set this limit to 20 processes.
preet@nymphadora:~/# echo 20 | sudo tee /sys/fs/cgroup/test_cgroup/pids.max
20
preet@nymphadora:~/#Step 3: Execute Processes Within the Cgroup
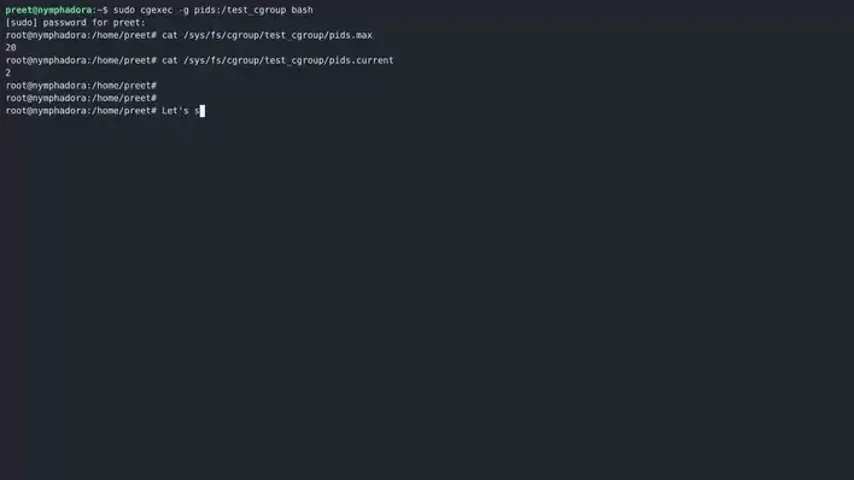
Now, let’s execute a bash shell within the “test_cgroup” using the cgexec command. This will confine the bash shell and any processes it spawns within our newly created cgroup.
preet@nymphadora:~/# sudo cgexec -g pids:/test_cgroup bash
root@nymphadora:/home/preet#
root@nymphadora:/home/preet# cat /sys/fs/cgroup/test_cgroup/pids.max
20
Any processes initiated from this shell will be subject to the resource limits defined for the cgroup.
Step 4: Test with Fork Bomb
Finally, let’s test our cgroup configuration by running a fork bomb script. Fork bombs are typically small scripts that rapidly spawn child processes until system resources are exhausted.
:(){ :|:& };:This command defines a fork bomb function (:) that recursively calls itself twice (:|:&), creating an exponentially growing number of processes. The semicolon at the end executes the function.
Observation:
With our cgroup configuration in place, the fork bomb script executed within the “test_cgroup” should be limited to a maximum of 20 processes. This prevents it from overwhelming the system and causing instability.
preet@nymphadora:~/# echo 20 | sudo tee /sys/fs/cgroup/test_cgroup/pids.current
20
preet@nymphadora:~/#To cleanup newly created cgroup
preet@nymphadora:~/# sudo cgdelete pids:/test_cgroupConclusion:
In this tutorial, we’ve demonstrated how to create an isolated namespace for docker container and cgroup in Linux, set resource limits for it, execute processes within the cgroup, and test its effectiveness against a fork bomb.



